

The best data quality examples are those that we encounter daily. Today I went to the dry cleaners to pick up my suit and what did I find? A great example of unclean data at the dry cleaners! I handed my ticket to the lady, who I later found out was the owner, and she initiated a friendly conversation about the name on the ticket while advancing the dry cleaner conveyor (the rack that holds hundreds of garments that have been cleaned and are ready for pickup). As #110 on the conveyor arrived, she verbally acknowledged that my suit was not there- which I clearly saw with my own eyes. At this point I have to admit I shifted uneasily wondering if there was going to be a problem. Very calmly however, she looked at the number, cross referenced a few other documents (the carbon copies of the order that she had pinned to the wall) and then advanced the conveyor to #210, where to my surprise- not so much hers- my suit was hanging. She calmly handed me the clothes and scratched out the #110 and replaced it with #210 with a wry smile of satisfaction.
Below I have provided a graphical illustration of the conveyor and the numbers discussed (sometimes the best way to solve quality issues is to draw them out). As you can see, the conveyor has a numbering system from 1 to 500, thereby allowing for a total of 500 positions to hang clean clothes.
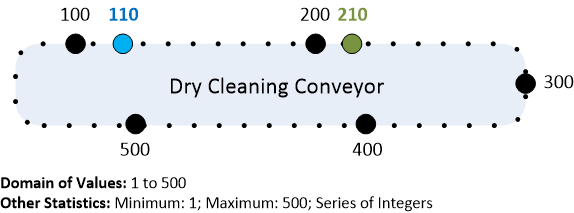
Although this process is much simpler than a multi hundred-million dollar software application with hundreds of application developers and thousands of sales agent interactions on a daily basis- I still found the parallels very apparent.
- This conveyor represented a finite domain of values from 1 to 500, somewhat akin to a unique numbering system for sales agents within a financial institution.
- There were additional documents (receipts pinned on the wall) that acted as controls and transactions with reference documentation.
- The system (conveyor numbering in this case) had a correlation with some real-world tangible object, which included hundreds of clothes, and specifically my suit.
At this point you likely want me to get to the point, so let me introduce the Conformed Dimensions of Data Quality that can be illustrated here. Following each dimension listed below is the underlying concept that can be used to further refine our segmentation of quality and help determine what metrics are suitable for measuring quality.
- Validity,Validity measures whether a value conforms to a preset standard.
- Values in Specified Range, Values must be between some lower number and some higher number.
We could evaluate the data that was recorded on the receipt, #110, which does fall within the valid range of values that can be observed on the conveyor, so it is plausible that my suit is hanging there somewhere. When evaluating the quality of data using validity an analyst can very quickly identify a frequently occurring error. For instance, if the number on the ticket said #40000 (well beyond the specified range as documented in the illustration above), the error would have been quickly identified. In the DQ field this evaluation of validity could have been quickly identified in bulk through the use of a data profiler which typically provides you the ability to explore observed domains or test for them.
- Integrity, Integrity measures the structural or relational quality of data sets.
- Referential Integrity, Referential integrity measures whether if when a value (foreign key) is used it must reference an existing key (primary key) in the parent table.
Like a well-tuned accounting system with controls, the way that the owner orders the transactional receipts (albeit on the wall) and links them via a unique receipt number, enables her to associate the line item detail (1 suit jacket, 1 pair of pants...etc) with the items on the conveyor. This enabled her to eliminate other items nearby that didn't include a man's jacket and pants.
At this point, however, she leveraged her institutional knowledge, she recalled that sometimes when staff place the clothes on the conveyor, they accidentally put them in the wrong position- but usually off by one digit (aka 210, 310, or 410 instead of 110). Because this is a single proprietor operation- and she personally knows the tricks to find the clothes- the solution is relatively straight forward. In a multi-billion dollar revenue organization with hundreds of departments and petabytes of structured (let along unstructured data) institutional knowledge is harder to find. This is why documentation- at a much larger scale is so important in larger organizations. Tools that enable better data management in terms of documentation include a metadata repository that lists the definitions of each field (e.g. the identifiers in the 1-500 domain). Or another effective tool is the use of an IT defect ticket system linked to the metadata repository fields providing the association between a data field in question and data quality defects filed in the past.
Lastly, but perhaps most importantly, the use of a unique identifier for each dry cleaning order links a number (its associated documentation) with the real-world item on the conveyor. This illustrates the Accuracy dimension's under lying concept of Agree with Real-world.
- Accuracy, Accuracy measures the degree to which data factually represents its associated real-world object, event, concept or alternatively matches the agreed upon source(s).
- Agree with Real-world, Degree that data factually represents its associated real-world object, event, or concept.
In conclusion, when you are learning the dimensions of data quality it helps to print the list of Conformed Dimensions and Underlying Concepts (here) and then run through which ones are most appropriate to measure the quality of the data available versus your expectations. A word of advice, don't try to use all of them at once, rather pick two or three that best fit your situation and provide the definitions of these to others when you explain the issue. As you begin to use them in context you'll begin to understand the truly multi-dimensional nature of data quality.