

Using the Conformed Dimensions of Data Quality when Training Machine Learning Programs
In November, Tejasvi Addagada from Dattamza, published an article espousing strong Data Governance when undertaking AI related projects, so we thought it’d be helpful to co-publish a series of blogs relating this and similar topics. With significant emphasis on Machine Learning these days, we thought it would be valuable if we shared some data quality struggles that our clients face during Machine Learning efforts. Over the next five blogs we’ll address challenges we see in the industry and most importantly we’ll provide data quality related solutions.
Data Related Challenge Categories:
- Wrong Data- Even though the business objective is clear, data scientists may not be able to find the right data to use as inputs to the ML service/algorithm in order to achieve the desired outcomes.
- Not Enough Data (generally history in the form of rows of data)- Either because a business didn’t know what data to collect, or because retention policies restricted the length of time- a company may not have enough data in order to sufficiently train their ML program.
- Not Enough Variety (aka attributes/columns)- Similar to Enough History (#2), a company may not have known that it needed to collect additional attributes (like sales channel, shipping method, time of day of purchase) of transactions conducted (say with the customer, partner, vendor, government…etc.). Sometimes this means that only aggregate data was collected- to save time or ensure simplicity- but is later needed at a granular level of detail.
- Bias- Nature of data collected somehow shows poor representation of reality, (too much data showing one situation but not another) and understanding that and mitigating that can be hard at best.
- Cleansing/Fixing- It’s said that 80% of a data scientist’s time is spent finding and cleaning and otherwise preparing data, but doing so is doubly costly if the issue isn’t identified at the source of the data and corrected in order to prevent future creation of poor quality data.
Blog 1 of 5: Finding the Right Data Required of Machine Learning (#ML)
The first Data Quality challenge is most often the acquisition of right data for ML Enterprise Use cases.
- Wrong Data- Even though the business objective is clear, data scientists may not be able to find the right data to use as inputs to the ML service/algorithm to achieve the desired outcomes.
As any data scientist will tell you, developing the model is less complex than understanding and approaching the problem/use-case the right way. Identifying appropriate data can be a significant challenge. You must have the “right data.”
So, what does it mean to have the right data?
Throughout the rest of this article, we describe the characteristics of the appropriate data for your analytical situation. To start with, you may have identified a set of attributes in your organization’s daily transactions such as the “channel last used”, which are likely predictors of customer behavior, but if your organization isn’t collecting these currently, you have a challenge. Having been caught in this situation, many data scientists believe that the more data collected the better.
Another option, however, is to clearly scope the collection of data required for the use case based on research about the sensitivities and relationships between existing data attributes. In other words, know your business and its data. By doing this up front, you’ll ensure that the time spent collecting new data isn’t wasted. Knowing this also enables you to define data quality rules that ensure that data is collected right the first time.
In the financial services space, the term Coverage is used to describe whether all of the right data is included. For example, in an investment management firm, there can be different segments of customers as well as different sub products associated with these customers. If, for instance, some customer transactions happen on one Point of Sale (POS 1 below) system but others on another (e.g. POS 2), or even via sales team spreadsheets (Elite Customer File), the selection of which transactions should be included in a learning dataset can be challenging.
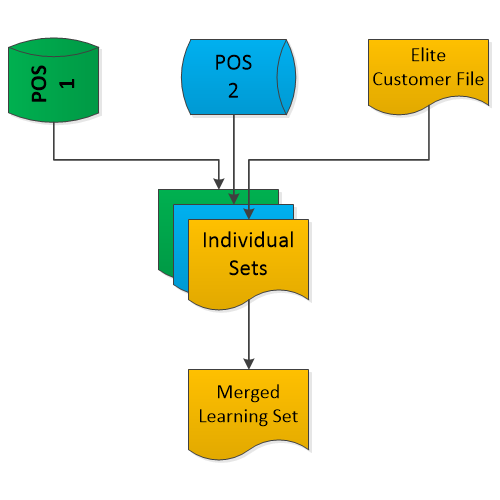
Without including all of the transactions (rows) describing customers and associated products, your machine learning results may be biased or flat out misleading. We point out that collecting ALL of the data (often from different sub entities, point of sale systems, partners…etc.) can be hard, but it’s critical to your success. Google's ML Rules advice by Martin Zinkevich cites this exact scenario in Rule #6. Through use of Data Quality dimensions, this task is easier.
More broadly speaking, what some people call Coverage, can be categorized under the Completeness Dimension of data quality and called the Record Population concept within the Conformed Dimensions standard. This should be one of the first checks to be performed before proceeding to other data quality checks.
With standard resources like the Conformed Dimensions of Data Quality (CDDQ), that explain the meaning of all of the possible data quality issues, you will not be bogged down in the cleansing work required later.
What are the Conformed Dimensions?
They are a standards based, comprehensive version of the dimensions of data quality that you’re already familiar with, such as Completeness, Accuracy, Validity, Integrity and other dimensions etc. The CDDQ offer robust descriptions of subtypes of data quality called Underlying Concepts of a Dimension and example DQ metrics for each of these.
The use of these DQ standards at the beginning of your exercise will ensure your data is the most fit for your purpose. In the next blog post, we’ll discuss what you can do when you don’t have enough data for the training phase of your project.